一个H2数据库源码Bug的定位之旅
版权申明:本文为原创文章,转载请注明原文出处
前言
整篇文章主要讲的是“遇到了一个什么样的Bug以及怎么定位找到它并解决的”,涉及到的知识点比较简单。
需要介绍一下H2和FitNesse,因为这是整篇文章的基础。
别紧张,只是简单了解一下。知道它们是个什么东西就行了。
H2数据库
H2数据库是什么?我们先看一下GitHub上介绍:
以我蹩脚的英语,可以知道有这几个特点:
非常快(very fast)、开源(open source)、基于磁盘(disk)或者内存(memory)
简单总结一下:
- H2是一个Java SQL database,它是一个开源的数据库,运行起来非常快。
- H2流行的原因是它既可以当做一个独立的服务器,也可以以一个嵌套的服务运行,并且支持纯内存形式运行。
- H2的jar包非常小,只有2M大小,所以非常适合做嵌入式数据库。
因为支持纯内存形式,所以在Java开发中,经常被作为单元测试的数据库。跑前插入,因为基于内存,跑后直接回收清除了。
OK,到这里,你已经大致了解了H2是一个什么东西了。
FitNesse
测试虽然很重要,但是覆盖测试用例需要花费很大的精力。
特别是一些复杂的功能,让开发同学去覆盖测试用例是不现实的。
而对于一些内层代码(如Service层代码),测试同学也不好介入测试。
那么,有没有一种工具,能让开发同学只关注开发,测试同学也能测试到内层代码呢?
有的!FitNesse就可以做到。
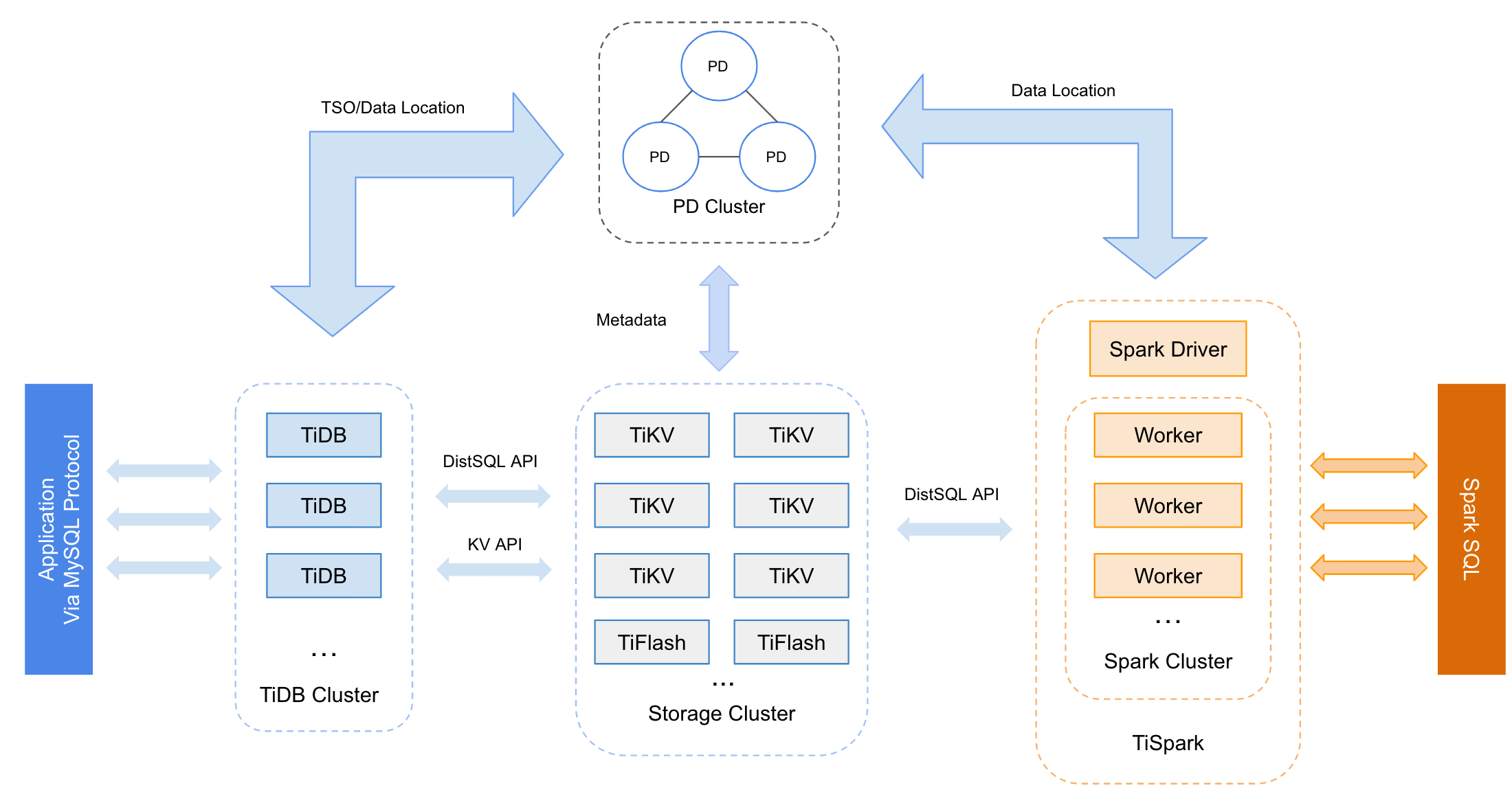
FitNesse架构图(来源:https://www.testwo.com/blog/4805)
这是FitNesse的架构图,简单来说呢,黄色的部分是需要开发的。
可以看做Test Cases模块是测试同学用wiki编写的测试用例。右边的Custom Fixtures和SUT模块是开发同学开发的一个测试接口。
可以简单的把它看做是一个自动化测试工具。开发同学只需要提供一个测试接口,然后测试人员可以通过写wiki的方式去写测试用例,让测试和开发独立开来。
如果是不理解,只需要知道FitNesse是一个可以跑测试用例的框架就行了
实践
以我们公司为例,我们将需要测试的一些业务抽成FitNesse接口,开发同学提供测试接口,让测试同学以写wiki的形式去覆盖测试用例。
FitNesse是支持跑单个测试用例的,也支持一次性跑多个测试用例,这一点和JUnit类似。
将环境搭建起来之后,测试同学把所有的测试用例覆盖,每天只需要定时通过脚本去跑这些测试用例就行了。
测试其实是一个验证输入——输出的过程,所以在测试覆盖度足够高的情况下,一个功能模块的全部测试用例都能跑通就能代表这个功能是没有问题的。
问题
为了保证各个测试用例直接的数据互不影响,我们在每个测试用例运行之前都清掉了缓存,并且TRUNCATE了所有的表。
TRUNCATE作用是清空表或者说是截断表,会清空表中的所有行,但表结构及其约束、索引等保持不变,会重置表的自增值;
理论上只要清空所有的缓存,重置所有的表,就不会有数据相互干扰的问题。
在实际环境中,出现了这样一个问题:
在生产环境自动化批量跑测试用例的时候,我们发现某些用例不能运行成功,一些表的自增主键没有重置。而这些用例单独跑是能够跑过的。
解决过程
考虑到两点:
- 就是是因为缓存的原因的话,也不至于1000个测试用例就这几个测试用例失败。
- 如果每个用例之前没有清空表的话,更加不可能只有这几个用例失败。
所以我直接就排除了缓存和清空表没有清空干净的问题。这个“想当然”为后面埋下了伏笔,很关键,记住,这要考的!
模拟失败用例
第一步,我先讲测试用例抽象到本地。写了很简单的一段代码,模拟了同时跑了两个测试用例,模拟了线上用例出错的情况。
从上面的结果,可以证明:TRUNCATE命令是能够重置主键id的
而上官方文档也说的很清楚,TRUNCATE命令是可以重置自增主键的。
Drop
DROP作用是删除表,会清空表里面所有的数据,删除表结构及其约束、索引;
上面的试验让我将矛头转向了缓存,但在我仔仔细细检查了缓存之后,已经可以确定所有的缓存都被清掉了。
这让我怀疑还是因为表的问题。于是乎,我尝试了一个很蠢的方法——每个用例之前,用DROP命令删掉所有的表,然后重新建表。
以试一试的想法重新跑了测试用例,没想到所有的测试用例都能跑通了。
但是因为每个测试用例之前都用DROP命令删掉了所有的表(有几百个表)并重新建表,这让测试用例运行时间变得很长。
缓存
那怎么解决因为DROP命令导致速度慢的问题呢?
我第一时间想法就是空间换时间,把使用过的表放到一个容器里面,每个测试用例之前只需要遍历容器删除使用过的表,然后重新建表。
在一个有几百个表的测试环境里面,每个测试用例可能用到的表最多也就10几个,这样下来能省下来一大部分的删表与建表的时间。而消耗的额外内存几乎可以忽略不计。
在使用这个方法调整了之后,跑1000个测试用例耗费的时间只有调整之前的一半了,效果是非常明显的。
Alter
那还不能更快呢?
我突然一想,为什么我要这么做呢?不就是数据库的自增主键没有初始化吗?那我用命令把他初始化不就可以了吗?
真是太愚蠢了!
因为H2的一些命令和Oracle相似,于是我在TRUNCATE命令之后,加了一条ALTER TABLE {表名} ALTER COLUMN {需要重置的列名} RESTART WITH 1的命令,将每一个表的自增主键重设为1。
这样改了之后,速度并没有比以前快,唯一好的一点就是不需要去单独维护使用过的表了,代码倒是精简了不少。
于是,这件问题暂时告一段落了。
越想越不对
下班回家之后,洗了一个苹果吃了起来,吃着吃着突然想起白天遇到的这个问题,越想越不对劲。
为什么1000多个用例就这几个用例有问题呢?而且还是固定的这几个呢?为什么我删了表再重新建表就没有问题了呢?
难道我上当了?
想来想去还是TRUNCATE命令的问题啊,就是这个命令没有把表清理干净啊。
难道说H2数据库有Bug?只是说这个Bug的触发条件我没有发现而已?
定位问题
开启Debug模式,当我觉得即将水落石出的时候,发现这H2源码太难追踪,层数太深,太难定位到问题。
果断打开GitHub,把H2的源码下载到了本地。
经过两个小时对H2源码的分析,发现了H2的源码将面向对象体现的淋漓尽致。
表是对象,索引是对象,每一个命令也都是对象。
等等!每个命令都是一个对象?那是不是TRUNCATE也对应一个类呢?
好家伙!还真被我找到了一个叫TruncateTable的类。
对数据库了解的人,上面这段代码并不难读懂。里面的Sequence需要给不了解一下Oracle的同学讲一下。
Sequence号是数据库系统按照一定规则自增的数字序列,因为自增所以不会重复。
Sequence的作用主要有两个方面:
- 作为代理主键,唯一识别;
- 用于记录数据库中最新动作的语句,只要语句有动作(I/U/D等),Sequence号都会随着更新,所以我们可以根据Sequence号来select出更新的语句。
- H2是这么干的:给创建的表的自增列(Column)建一个代理主键Sequence。
知道了Sequence是干什么用的之后,我们再来回看这段代码:
- 其中1部分可以理解为清理表,
- 2部分可以理解为重置自增列,3部分是判断是否需要重置自增列
简单翻译一下3部分的代码:如果自增列的当前值不等于最小值,就重置,否则没有这个必要。
这句话是不是咋一看没什么毛病?
好的,我们 重跑一下上面模拟的测试用例:
先插入两条数据,然后TRUNCATE表看着里面干了什么。
按照这句话我们推理一下:如果自增列的当前值不等于最小值,就重置,否则没有这个必要。
因为 currentValue = value - increment且Value = 3,increment = 1,minValue = 1
所以 currentValue = 3 -1 = 2
所以 min != currentValue
所以需要重置自增列,将自增列对应的Sequence的value设置成min,也是就1。
上面的逻辑是不是天衣无缝?没有一点问题?
按照上面的逻辑:
插入2条数据,TRUNCATE表,将value从3重置为1
插入3条数据,TRUNCATE表,将value从4重置为1
插入4条数据,TRUNCATE表,将value从5重置为1
…
是不是可以得到:
插入1条数据,TRUNCATE表,将value从2重置为1
但是实际上插入一条数据再TRUNCATE表会怎么样呢?我们Debug一下:
因为 currentValue = value - increment且Value = 2,increment = 1,minValue = 1
所以 currentValue = 2 -1 = 1
所以 min == currentValue,这个很关键,不满足条件了,不会去重置表了。
所以插入1条数据,TRUNCATE表,不会将value从2重置为1,下次去取值的时候,取到的就是2而不是我们想要的1。
所以这个地方的判断逻辑明显是有问题的。
H2,你不对劲!你不讲武德啊!将一个Bug埋得这么深!
后续
碰到这个的Bug谁顶得住啊,于是我查看了GitHub上最新的代码。
好家伙!已经修复了这个问题,直接把那个有Bug的那个判断去掉了。
不对劲啊,我们项目使用的就是最新版的H2啊。
进到mvnrepository一看,“打开了mvnrepository,发版记录停步去年的深秋”,这真是H2版本的《灰色头像》啊。
最新版本是19年十月份发的,现在都已经20年12月了,都一年多了,还不发新版?
于是乎,我跑到GitHub上提了一个issue指出了这个问题,并且希望作者能够早日发布新版。
作者第二天回复了我,大致意思就是说这个问题已经解决了,就不需要去管它了,然后把我的issue关闭了,并甩给了我了一个关于新版发布计划的讨论地址。
大致看了一下他们的讨论,作者的意思总结来说就是新版有很多兼容处理没有做好,所以最近发布新版没戏!
我提的issue地址:https://github.com/h2database/h2database/issues/2978
有兴趣的小伙伴可以去看一下。
结论
总结一下:
H2数据库使用TRUNCATE命令去重置表的时候,如果表里面有一条数据的话,是不会重置自增列的。
这是H2的一个Bug,在下一个版本会修复,但是现在看起来下个版本遥遥无期。
这是一个蛮有意思的故事,整个过程充满了“悬疑和猜忌”,最后找出“罪魁祸首”。
后面再去回顾我的解决思路,发现很多地方都是不严谨的,有很多想当然。
好在最后吃苹果的时候想起来了不对劲最后找到了问题,看来还是要多吃苹果。
写在最后
我是CoderWang,一个Java程序员。
我们下期再见!
更多精彩微信公众号搜索“CoderW”,我们一起进步!
文章中涉及代码:https://github.com/xiaoyingzhi/blog
FitNesse官网:http://www.fitnesse.org
一个H2数据库源码Bug的定位之旅